
 Deep learning
Deep learning
Il progresso dei moderni computer corre sempre più veloce, con la formazione di nuovi campi di ricerca e di sperimentazione. Oggi possediamo delle macchine capaci di distinguere, data un'immagine di input, un cane da un gatto, oppure un'auto da una moto, e così via. Affidare tali compiti ad un computer era impensabile una decina di anni fa, ma i moderni algoritmi di machine learning e di computer vision hanno fatto passi da gigante. Questi due campi sono così andati incontro a nuove scoperte e innovative tecniche che in un periodo piuttosto stretto hanno portato a dei risultati strabilianti.
Il deep learning è uno dei campi che può essere etichettato come nuovo, che sta accompagnando e accompagnerà per mano lo sviluppo di moltissimi settori applicativi, come quello dell'intelligenza artificiale o delle auto a guida autonoma.
Le reti neurali sono la base
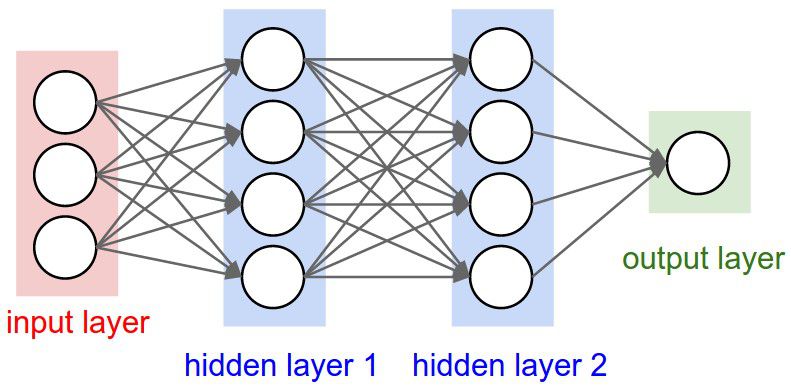
Il deep learning (o apprendimento approfondito, in lingua italiana) è un termine che indica un particolare approccio alla progettazione, allo sviluppo, al testing e soprattutto al traning delle reti neurali. I neural network sono nati nel 1950 e, così come tanti altri campi di ricerca quali la fisica quantistica o il nucleare, sono andati incontro a numerosi intoppi nei cinquant'anni successivi, probabilmente a causa dei limiti delle tecnologie dell'epoca. Sin dalla loro nascita, però, le reti neurali sono state etichettate dagli esperti come uno dei settori della scienza più promettenti.
Le reti neurali sono capaci di prendere delle decisioni in tutta autonomia, basandosi sugli input del sistema, che comprendono anche le variabili d'errore. È grazie a queste che i sistemi basati su reti neurali riescono a migliorarsi col passare delle iterazioni, il tutto senza l'intervento umano. Cercando di semplificare il più possibile il loro funzionamento, in ingresso ad una rete neurale spesso troviamo un vettore numerico, che può rappresentare svariate tipologie di dati: pixel, segnali audio, segnali video o parole sono solo alcuni degli esempi possibili. Il vettore in input viene generalmente trasformato mediante una serie di funzioni che lavorano sul vettore stesso, ed il risultato costituisce l'output generato dalla rete. La grossa particolarità delle neural network è che il prodotto del sistema è la predizione di alcune proprietà che la rete stessa cerca di indovinare dall'input ricevuto. Un esempio banale può essere quello in cui in ingresso alla rete neurale abbiamo un'immagine e, sulla base di alcune funzioni, essa cerca di indovinare se nella foto ci siano o meno delle automobili.

Chiaramente, le funzionalità del sistema vengono gestite dal cervello, che in questo caso è una memoria contenente a sua volta altri vettori di numeri noti come "pesi". Questi ultimi definiscono come gli input della rete devono essere combinati e ricombinanti per produrre un risultato quanto più affidabile possibile. Più la problematica da affrontare è complessa e più i pesi diventano grandi (in termini informativi). Riconoscere un'automobile all'interno dell'immagine, ad esempio, può essere un compito relativamente arduo, in dipendenza della qualità, dalla linearità poligonale o dalla spazialità degli oggetti presenti nella foto. Il compito più difficile di un progettista di una rete neurale è infatti proprio la definizione dei pesi, e di che "valori" questi devono assumere per far sì che il sistema faccia un buon lavoro nel momento in cui ci sia la necessità di generare una predizione.
Il training si fa col deep learning
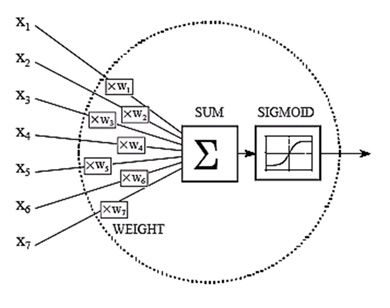
Le reti neurali sono implementate in macchine capaci di apprendere dalle previsioni sbagliate. Queste devono infatti essere conosciute (e quindi messe in input) dal sistema, che le deve analizzare, capire e correggere. Durante il processo di inizializzazione di una rete neurale i valori degli array costituenti i pesi vengono, all'incirca, assegnati in maniera randomica, per poi essere aggiustati man mano che la macchina apprende. L'obiettivo principale di una rete neurale è infatti proprio quello di sistemare, iterazione dopo iterazione, i valori dei pesi, in maniera tale che la predizione successiva sia più precisa di quella immediatamente precedente. Detto così può sembrare semplice, ma in realtà non lo è, soprattutto negli scenari più complicati. Istruire una rete neurale ad imparare è un compito molto complesso, ancora di più se pensiamo ad ambiti quali il riconoscimento vocale, la computer vision o le auto a guida autonoma.
Senza ombra di dubbio la potenza computazionale è di primaria importanza per una rete neurale di qualità, e solo negli ultimi anni si è arrivato all'utilizzo delle schede grafiche, che vengono sfruttate in parallelo per accelerare in maniera notevole il processo di predizione dell'output.
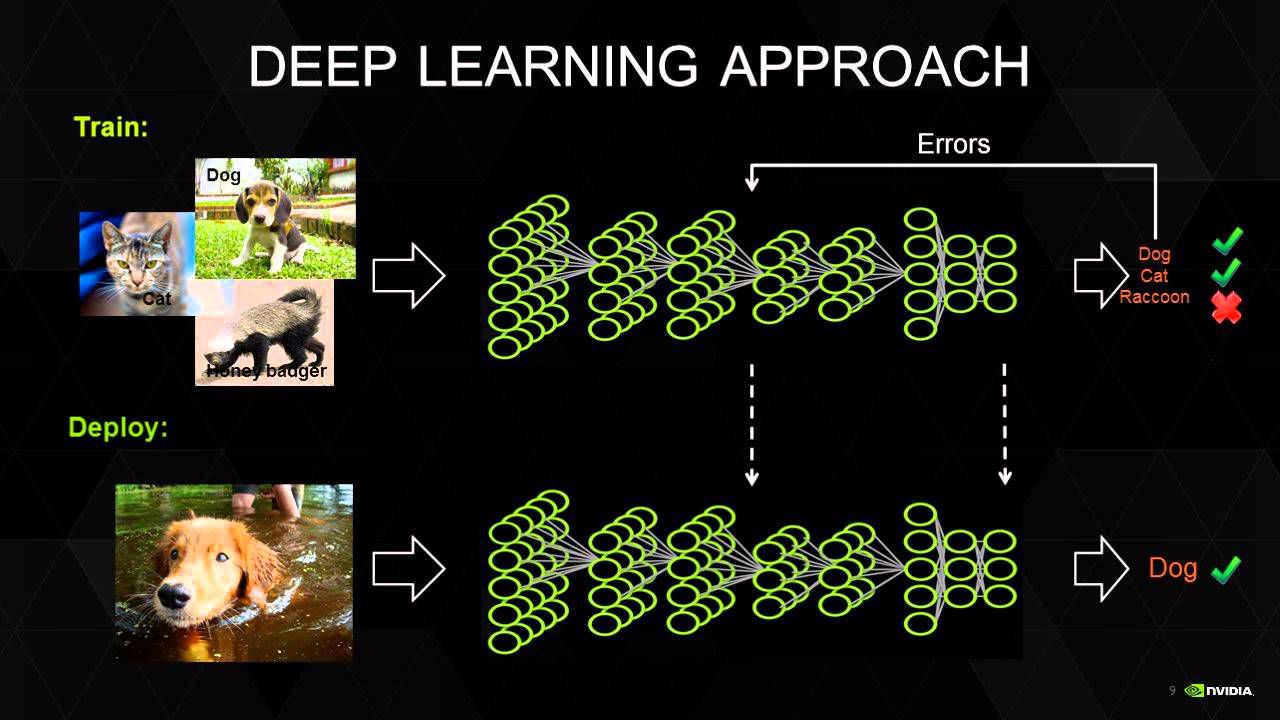
In definitiva, l'insieme hardware e software consente di applicare nella pratica il deep learning, che a sua volta permette di effettuare il training delle reti neurali. È grazie al deep learning che queste ultime sono in grado di imparare (e da qui il termine "apprendimento approfondito"), di gestire sempre meglio gli input, di auto-costruirsi dei modelli via via più complessi ed efficienti e di giungere a predizioni sempre più corrette, fino a risolvere il problema di interesse in maniera sempre più accurata.
Come apprendono le macchine
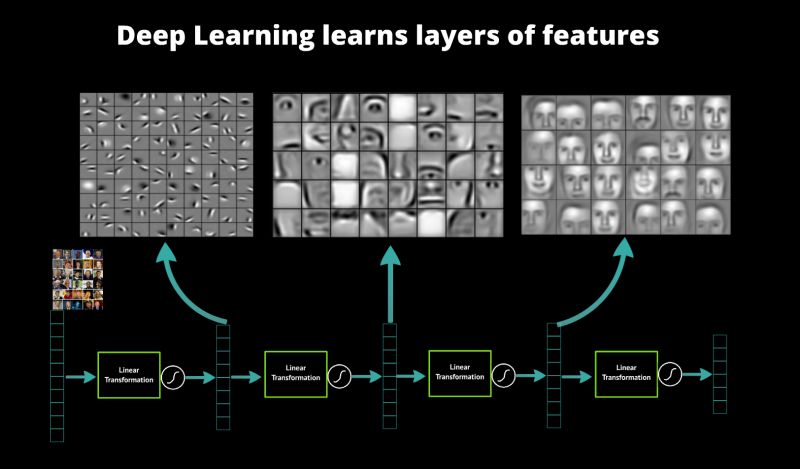

Qual è, a questo punto, il criterio principale per insegnare una macchina ad imparare? Ciò che una rete neurale deve saper effettuare è l'analisi delle informazioni nude e crude derivanti dall'ingresso. Una volta che l'input è stato analizzato e impacchettato, le neural network sono in grado di estrarre le sue proprietà caratterizzanti, che stanno alla base dell'apprendimento. Con l'approccio convenzionale tali proprietà erano identificate manualmente, facendo leva sul registrare in memoria le caratteristiche dei pattern di input: in sostanza, venivano dati in pasto alla rete neurale degli input conosciuti e, per ognuno di questi, si memorizzavano le proprietà principali, un lavoro molto lungo. Quando il sistema riceveva un input già analizzato in passato, riconosceva la similitudine ed era capace di estrarre le caratteristiche di interesse, in quanto si trattava di un caso già visto. Chiaramente, quanto più vari erano gli input tanto più flessibile era la rete neurale.
Il deep learning rimuove l'intervento umano e, quindi, la necessità di porre alla macchina ingressi conosciuti per istruirla all'identificazione delle proprietà più "frequenti".
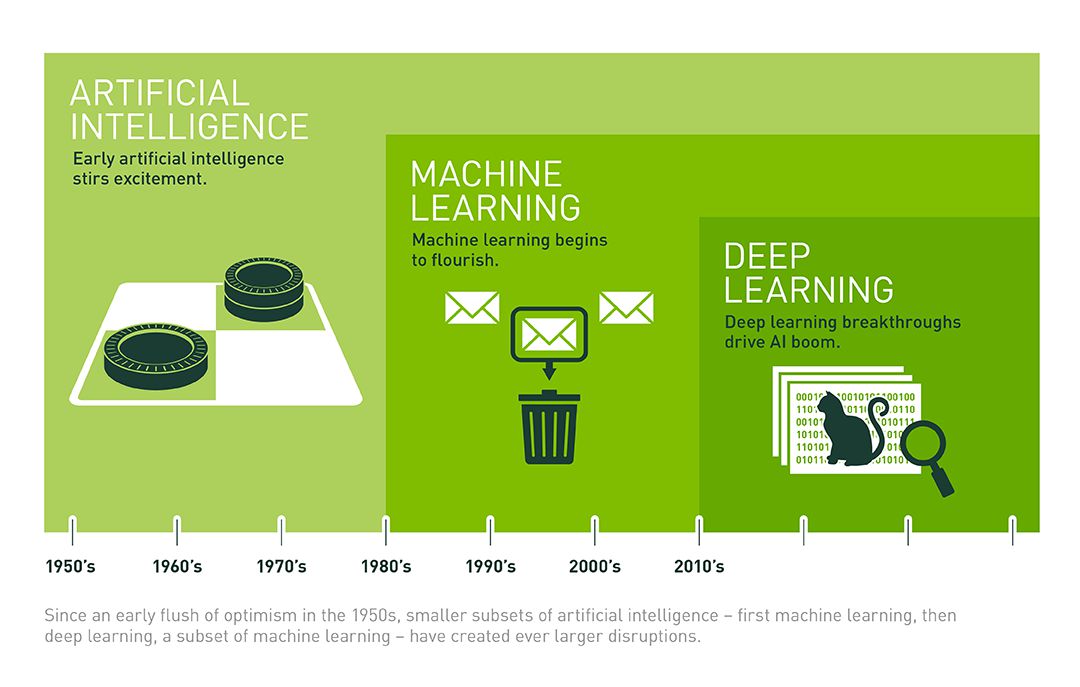
Questo impone comunque ai progettisti delle scelte più oculate e mirate, rendendo però la macchina anche più versatile. Il nuovo approccio legato al deep learning rende infatti le reti neurali più generaliste e meno mirate, rimuovendo i limiti imposti dalle serie di input del metodo tradizionale. Le reti neurali sono diventate così utili su una svariata tipologia di contesti: dall'intelligenza artificiale al riconoscimento vocale, passando per la computer vision, per le identificazioni legate all'audio (avete in mente Shazam?) e per le auto a guida autonoma.
 Il deep learning sarà un tassello essenziale dello sviluppo in tantissimi settori. Fino al momento in cui diventerà effettivamente qualcosa di più concreto e testato rimarrà oggetto “misterioso” da scoprire e sviscerare, capace però di racchiudere un potenziale davvero enorme. L’apprendimento approfondito può rendere semplici compiti che prima non lo erano affatto. Ciò che abbiamo scoperto in questo articolo sono comunque le basi del campo di ricerca, e da discutere c’è molto altro, tra cui altri concetti fondamentali e le varie tipologie di apprendimento (convolutional, reinforcement learning, sequence learning...), che vedremo nel prossimo speciale dedicato.
Il deep learning sarà un tassello essenziale dello sviluppo in tantissimi settori. Fino al momento in cui diventerà effettivamente qualcosa di più concreto e testato rimarrà oggetto “misterioso” da scoprire e sviscerare, capace però di racchiudere un potenziale davvero enorme. L’apprendimento approfondito può rendere semplici compiti che prima non lo erano affatto. Ciò che abbiamo scoperto in questo articolo sono comunque le basi del campo di ricerca, e da discutere c’è molto altro, tra cui altri concetti fondamentali e le varie tipologie di apprendimento (convolutional, reinforcement learning, sequence learning...), che vedremo nel prossimo speciale dedicato.





