
 NVIDIA
NVIDIA
La capacità di calcolo dei moderni processori grafici è enorme, ed essa è cresciuta tantissimo negli ultimi anni. Le prestazioni delle GPU aumentano ad un ritmo di gran lunga più sostenuto di quelle delle CPU, ma le richieste delle applicazioni sono sempre maggiori. Software che effettuano complessi calcoli scientifici, per esempio, spesso e volentieri hanno bisogno di più schede grafiche in parallelo per essere efficienti. Il problema, però, è che lo scaling con due o più GPU non è perfetto, e nella pratica tale fattore peggiora al crescere del numero di schede grafiche utilizzate. Forse è per questo motivo che la maggior parte dei computer consumer oggi fa utilizzo di un solo processore grafico. Gli appassionati sono gli unici a possedere sistemi con schede video multiple, che permettono di ottenere un aumento del framerate nei propri titoli preferiti - o semplicemente di raggiungere un punteggio più elevato in un determinato benchmark. Difficilmente gli utenti enthusiast vanno oltre le due schede grafiche, perché installare tre o quattro GPU non è così conveniente. Oggigiorno anche il più veloce processore consumer, l'Intel Core i7-5960X, mette a disposizione 40 linee PCI Express 3.0, un vero collo di bottiglia se le schede video installate nel sistema sono quattro; in tale circostanza, infatti, la velocità dei bus PCie scende a x8. Nel settore professionale c'è invece largo impiego di un quartetto di schede video in parallelo, perché le applicazioni di simulazione, deep learning e calcolo complesso necessitano di tantissima potenza grafica. Se fosse possibile, i professionisti andrebbero anche oltre i quattro processori grafici, ma attualmente c'è un limite imposto dall'interfaccia PCI-E e dalla tecnologia SLI. NVIDIA ha però tutta l'intenzione di proporre una concreta soluzione a questi problemi, che presenterà insieme alla GPU Pascal. Si tratta di NVLink, una tecnologia che apre nuovi scenari, soprattutto nell'utilizzo delle GPU in campo professionale.
Da dove nasce NVLink?

L'accelerated computing sta diventando una pratica sempre più comune nel settore dell'high performance computing (HPC). Nel 2012, il Titan dell'Oak Ridge National Laboratory è diventato il supercomputer più veloce al mondo. A bordo ha una scheda grafica NVIDIA per ogni processore installato, degli AMD Opteron Opteron 6274, che sono riuscite ad infrangere numerosi record. Se pensiamo che la capacità di elaborazione è fornita per il 90% dalle GPU, è facile comprendere come questo elemento sia essenziale nell'influenzare le performance. Nell'ultimo periodo però si sta già discutendo sui successori del Titan, che dovrebbero essere chiamati Summit - ubicato sempre all'Oak Ridge - e Sierra, situato invece nel Lawrence Livermore National Laboratory. Ci si aspetta che entrambi i sistemi forniscano delle prestazioni di picco pari a ben 100 petaFLOPS, che possono derivare solo dalla massima ottimizzazione nella gestione parallelismo tra GPU e tra CPU e GPU. Il problema, a questo punto, è capire come far dialogare meglio questi elementi. Attualmente, gli sviluppatori sono costretti ad amministrare con moderazione gli accessi al singolo chip grafico a mezzo del PCIe, perché tale interfaccia mostra oramai il peso del tempo, soprattutto in ambienti professionali e server. Ed è proprio qui che è intervenuta NVIDIA, introducendo una nuova modalità di comunicazione, NVLink. Essa costituirà l'ossatura di alcuni supercomputer di prossima generazione, e secondo l'azienda di Santa Clara può garantire uno scambio dati dalle 5 alle 12 volte più veloce rispetto ad oggi. NVLink potrebbe rappresentare una validissima alternativa al PCIe, spingendo Summit e Sierra a un livello più alto del resto dei computer exascale.
NVLink: aspetti essenziali

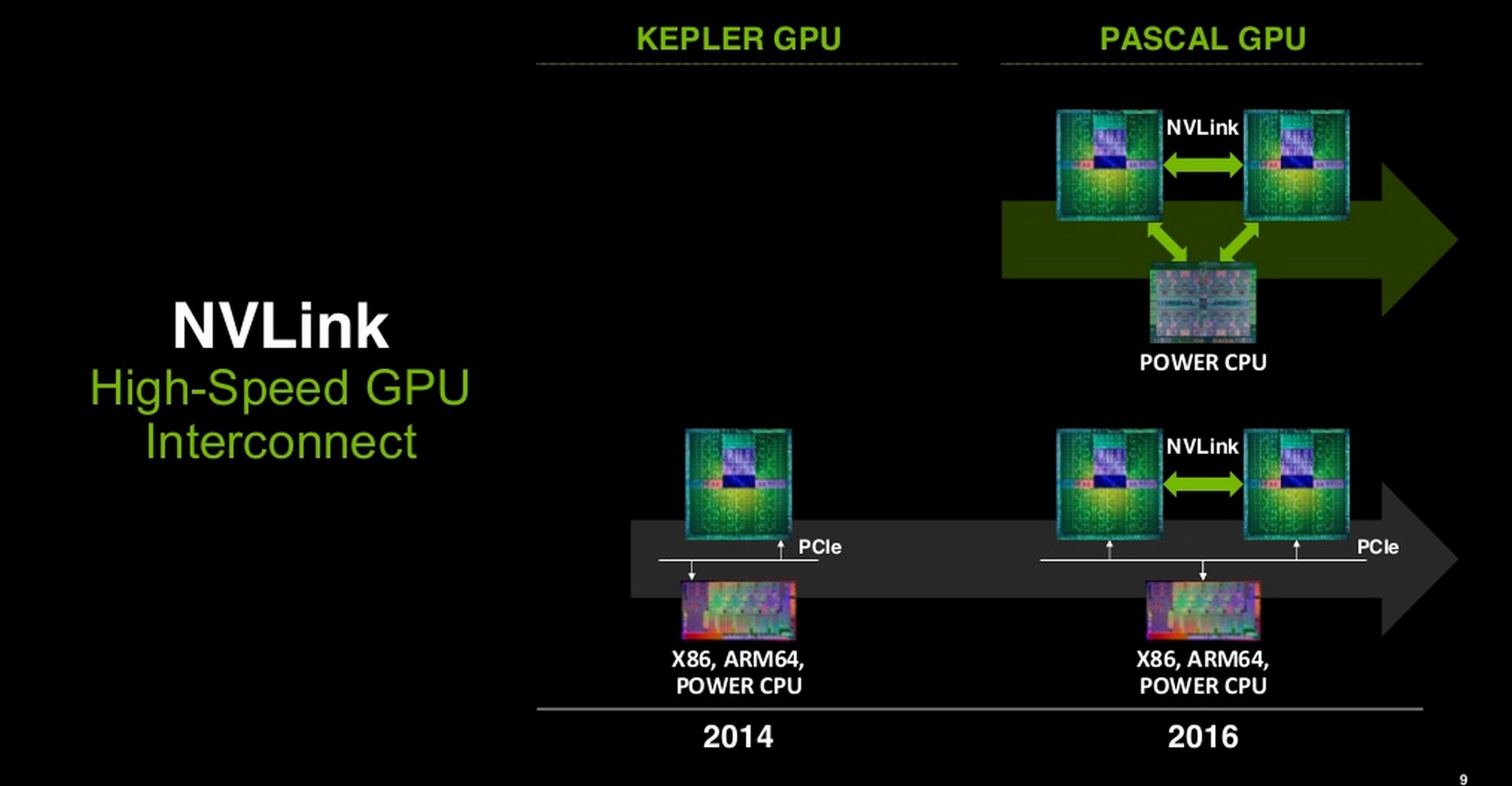
NVIDIA NVLink costituisce un insieme di protocolli PCIe che legano tutte le GPU tra loro e con il processore stesso, a patto che tutti i componenti abbiano delle porte specifiche. Le schede video Pascal in arrivo quest'anno avranno di certo le suddette porte, che si chiameranno proprio NVLink. Le GPU Pascal dovrebbero avere a disposizione un bandiwidth già più elevato del PCI Express, con una banda teorica di 80 GB/s (fra due chip grafici). Le GPU Volta porteranno questo valore ancora più in alto, sino a ben 200 GB/s. Dato l'enorme transfer rate, i supercomputer Summit e Sierra dovrebbero basarsi proprio sulle GPU con architettura Volta, oltre che su processori IBM Power9, gli unici a supportare NVLink.
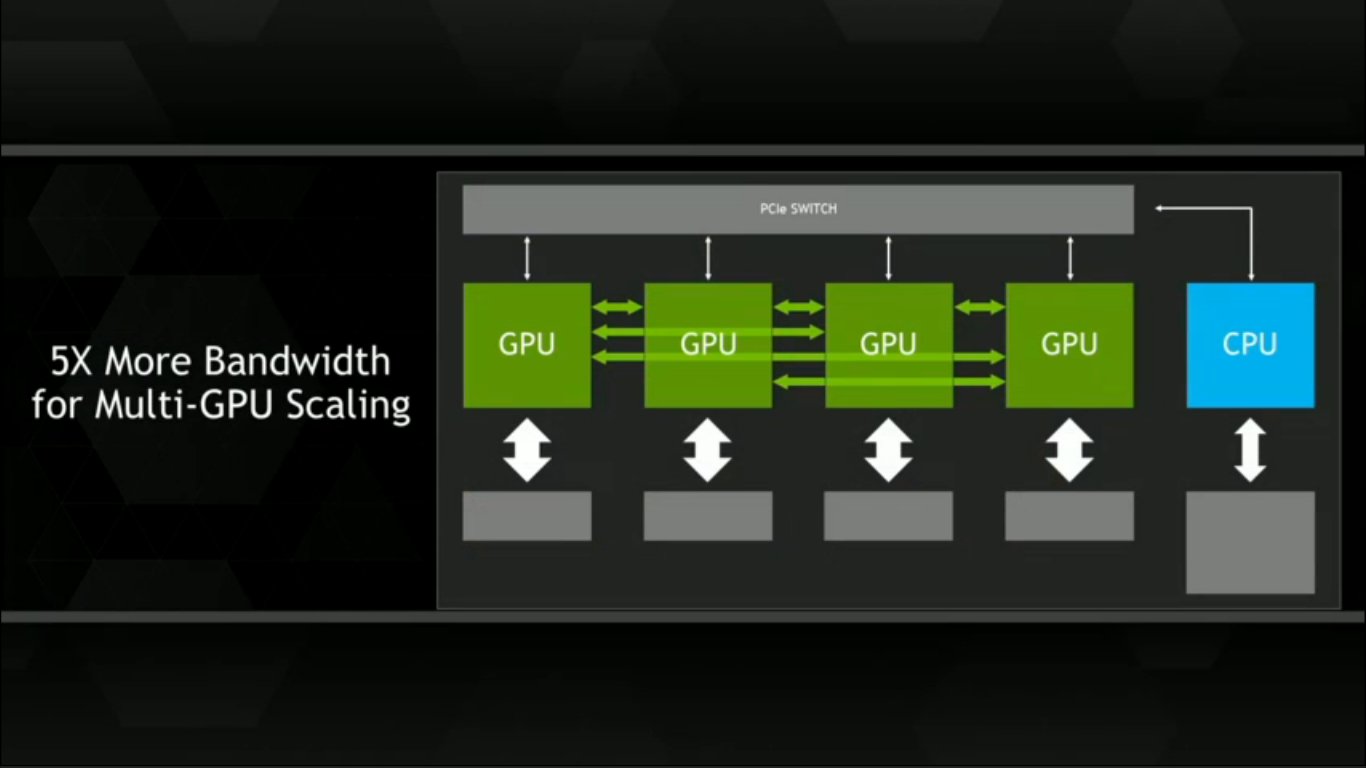
Grazie ad esso sarà possibile colegare due, quattro, sei o addirittura otto processori grafici fra loro, anziché via bus PCIe. Le sedici linee di uno slot PCIe 3.0 x16 sono capaci di generare una larghezza di banda che, al suo picco, consente di inviare circa 16 GB/s di dati. In un ambiente reale, però, i 16 GB/s si riducono a 12, a causa di un overhead che in uno scenario ideale non viene considerato. Ogni linea NVLink fornisce invece un bandwidth che in teoria arriva sino a 20 GB/s. Considerando che tra due GPU possono coesistere un massimo di quattro linee NVLink, il transfer rate arriva sino ad 80 GB/s - 64 GB/s tenendo conto degli effetti dell'overhead. Facendo due rapidi conti, ci accorgiamo di come le migliorie raggiungano un fattore moltiplicativo pari a cinque, ovviamente a vantaggio della nuova tecnologia NVIDIA. La situazione non è differente se i processori grafici sono tre o quattro: il concetto base è che da ogni scheda grafica le linee NVLink in uscita devono essere quattro. Quindi, prendendo come riferimento uno scenario con 3 GPU in SLI, per la prima scheda dobbiamo trovare due linee che vanno alla seconda ed altre due che vanno alla terza.
I processori grafici dialogheranno con la CPU servendosi però ancora del vecchio protocollo, cioè a mezzo di uno switch PCI Express. Un singolo switch PCIe può essere sfruttato da un massimo di tre GPU; se le schede grafiche installate sono quattro, gli switch da usare salgono a due. Tra GPU e processore rimarrà quindi lo scambio dati tramite le comuni linee PCIe x16; questo almeno alla prima iterazione di NVLink, poiché in futuro è possibile che la situazione cambi radicalmente qualora Intel e/o AMD aderissero al nuovo protocollo. Attualmente, l'unica azienda che ha confermato l'utilizzo di porte NVLink sui propri processori è stata IBM, il che potrebbe portare altre aziende a seguire il suo esempio.
I primi risultati di NVLink 1.0

NVIDIA ha fornito agli appassionati un primo assaggio dell'incremento prestazionale portato da NVLink. La società ha infatti realizzato una serie di test su macchine basate su due GPU Tesla con architettura Pascal. I punteggi sono stati registrati in due scenari diversi: nel primo, le schede grafiche facevano completamente uso del protocollo PCie, sia per comunicare fra loro che con la CPU, mentre nel secondo le Tesla erano legate dalle nuove linee NVLink.
Con il calcolo fluidodinamico di ANSYS Fluent si è avuto il miglioramento più basso, pari al 25%. Un algoritmo di ordinamento Multi-GPU, il test con LCQD QUDA e l'applicazione per il calcolo della dinamica molecolare AMBER hanno sfiorato un incremento prestazionale del 50%. E' quando si effettuano computazioni sfruttando il metodo Fast Fourier Transform 3D (FFT 3D) che si ottengono i benefici più elevati da NVLink: i risultati sono infatti pronti in meno della metà del tempo impiegato da PCIe 3.0. Purtroppo, NVIDIA non ha condotto sperimentazioni con più di due GPU e non sappiamo quali siano i vantaggi in tale circostanza.
I miglioramenti saranno ancora più importanti con un eventuale NVLink 2.0 dell'architettura Volta. Se i produttori di CPU fossero favorevoli, NVIDIA potrebbe creare una linea NVLink libera di dialogare direttamente con il socket del processore, aumentando ancora di più le prestazioni dei sistemi compatibili con questo standard.
 Come da prassi, il settore professionale sarà il primo a beneficiare delle nuove tecnologie, e la commercializzazione di NVLink avverrà dapprima nei supercomputer più veloci al mondo. Come abbiamo visto, IBM vuole applicare la tecnologia ai processori utilizzati nei suoi supercomputer, testimoniando l’utilità di NVLink nell’ambito dell’high performance computing. Non è tutto a favore del solo settore professionale, poiché la larghezza di banda extra fornita dalla nuova tecnologia NVIDIA potrebbe consentire agli utenti di costruire computer con addirittura otto schede grafiche in parallelo. Attualmente, però, l’azienda americana è impegnata a cercare un modo per impiegare efficacemente otto GPU per il rendering, anziché solo per il calcolo scientifico. Se NVIDIA fosse capace di gestire il parallelismo con efficienza, sostituendo quindi lo SLI con l’NVLink, i videogiocatori di tutto il mondo ne sarebbero certamente felici. Si risolverebbe così uno degli inconvenienti più grossi delle schede grafiche in parallelo, e cioè lo scaling. Affiancando una seconda GPU alla singola già presente nel sistema le prestazioni non raddoppiano mai, ma tra qualche tempo questo potrebbe essere solo un vecchio, dimenticato, scenario.
Come da prassi, il settore professionale sarà il primo a beneficiare delle nuove tecnologie, e la commercializzazione di NVLink avverrà dapprima nei supercomputer più veloci al mondo. Come abbiamo visto, IBM vuole applicare la tecnologia ai processori utilizzati nei suoi supercomputer, testimoniando l’utilità di NVLink nell’ambito dell’high performance computing. Non è tutto a favore del solo settore professionale, poiché la larghezza di banda extra fornita dalla nuova tecnologia NVIDIA potrebbe consentire agli utenti di costruire computer con addirittura otto schede grafiche in parallelo. Attualmente, però, l’azienda americana è impegnata a cercare un modo per impiegare efficacemente otto GPU per il rendering, anziché solo per il calcolo scientifico. Se NVIDIA fosse capace di gestire il parallelismo con efficienza, sostituendo quindi lo SLI con l’NVLink, i videogiocatori di tutto il mondo ne sarebbero certamente felici. Si risolverebbe così uno degli inconvenienti più grossi delle schede grafiche in parallelo, e cioè lo scaling. Affiancando una seconda GPU alla singola già presente nel sistema le prestazioni non raddoppiano mai, ma tra qualche tempo questo potrebbe essere solo un vecchio, dimenticato, scenario.





